
sql基础
start with 递归查询
当一张表出现层级关系,需求查询树状结果
例图:
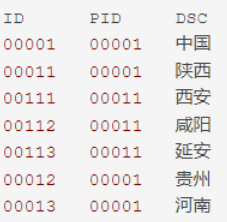
1 | Select ID, PID, DSC, LEVEL |
nocycle : 跳出循环
prior :
prior放在子节点端,则表示扫描树是以start with指定的节点作为根节点从上往下扫描。可能对应一个或多 个分支。
start with可以省略,如果省略,表示对所有节点都当成根节点分别进行遍历prior放在父节点端,则表示扫描树是以start with指定的节点作为最低层子节点,从下往上扫描。顺序是子节点往父节点扫描,直到根节点为止,这种情况只能得到一个分支。
Group By 字句增强 grouping sets使用grouping sets代替多次union
例:
1
2
3
4
5
6
7
8select DEPARTMENT_ID,JOB_ID,null as MANAGER_ID,max(SALARY),min(SALARY)
from EMPLOYEES
group by (DEPARTMENT_ID, JOB_ID)
union
select null as DEPARTMENT_ID,JOB_ID,MANAGER_ID,max(SALARY),min(SALARY)
from EMPLOYEES
group by (JOB_ID,MANAGER_ID)
order by DEPARTMENT_ID;代替
1
2
3select DEPARTMENT_ID,JOB_ID,MANAGER_ID,max(SALARY),min(SALARY)
from EMPLOYEES
group by grouping sets ( (DEPARTMENT_ID, JOB_ID), (JOB_ID,MANAGER_ID));sql优化
数据类型
使用最小合适的数据类型,如能使用tinyint不适用int
使用时设置合适的长度,如name varchar(30)
尽量避免bull
大表创建索引优化查询速度
索引包含多列,注意MySQL只能高效使用最左前缀列
使用索引时将索引单独放置比较符号一侧
查询使用到多个索引时把选择性最高的列放到最前,即区分精度最高的列
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.



