前言 本次实践的目的是结合之前所学flume、hadoop、hive几个主要技术,完成一个小案例。
准备 安装并配置好flume、hadoop、hive hive安装配置 hadoop安装配置 数据源 nginx日志文件access.log
1 2 10.88.122.105 09:15:04 GET /js/pagination.js HTTP/1.1 304 0 "http://10.88.105.20:8063/stockrecommand.html" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)"
修改hdfs默认配置 因为我的网站每天只产生很少的数据量远小于hdfs默认的(128M)块大小因此为避免空间浪费需修改默认块大小
1 2 3 4 5 6 7 8 9 10 #修改默认块大小 <property > <name > dfs.blocksize</name > <value > 10240000</value > </propery > #修改检查块大小 满足块大小整除检查块大小 <property > <name > dfs.bytes-per-checksum</name > <value > 512</value > </property >
yran资源管理器配置 在用hive操作时使用的内存会大于默认分配的资源因此需修改
1 2 3 4 5 6 7 8 9 #使用物理内存大小 <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 2048</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 2048</value > </property >
flume采集方案 1 cd /export/servers/flume/conf/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1 agent1.sources.source1.type = exec agent1.sources.source1.command = tail -F /www/wwwlogs/139.198.168.168.log agent1.sources.source1.channels = channel1 agent1.sinks.sink1.hdfs.path =hdfs://master:9000/weblog/year=20%y/month=%m/day=%d agent1.sinks.sink1.hdfs.filePrefix = mylog agent1.sinks.sink1.hdfs.fileType = DataStream agent1.sinks.sink1.hdfs.writeFormat = Text # 当文件滚动 生成新文件 # 配置文件滚动方式(文件大小10M) #8M agent1.sinks.sink1.hdfs.rollSize = 8000000 agent1.sinks.sink1.hdfs.rollCount = 0 agent1.sinks.sink1.hdfs.rollInterval = 0 # 指的是正在写的hdfs文件多长时间不更新就关闭文件 agent1.sinks.sink1.hdfs.idleTimeout = 5 agent1.sinks.sink1.hdfs.minBlockReplicas = 1 # 向hdfs上刷新的event的个数 # 这三者之间的关系:batchsize <=transactionCapacity<=capacity # 就是sink会一次从channel中取多少个event去发送,而这个发送是要最终以事务的形式去发送的 agent1.sinks.sink1.hdfs.batchSize = 10 # 我们打算对时间戳根据分钟以每10分钟为单位进行四舍五入。 # agent1.sinks.sink1.hdfs.round = true # agent1.sinks.sink1.hdfs.roundValue = 24 # agent1.sinks.sink1.hdfs.roundUnit = hour agent1.sinks.sink1.hdfs.useLocalTimeStamp = true #使用通道在内存中缓冲事件 agent1.channels.channel1.type = memory agent1.channels.channel1.keep-alive = 120 # capacity是指整个队列的缓存最大容量 agent1.channels.channel1.capacity = 1500 # transactionCapacity则是指事务event的最大容量,即每次传输的event最大为多少 agent1.channels.channel1.transactionCapacity = 100 #将源和接收器绑定到通道 agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1 agent1.sinks.sink1.type = hdfs
启动flume采集
1 2 3 4 5 6 7 nohup flume-ng agent --conf /export/servers/flume-1.9.0/conf --conf-file flume-spark-push.properties -name a1 >> /export/data/flume/loglisence.log &
查看收集的记录
HIVE操作 首先在hive创建日志表,
1 2 3 4 5 6 7 8 9 create external table mlog(ip string,mtime string, url string, respCode int , header string) partitioned by (year string,month string,day string) row format delimitedfields terminated by '\t' ; location 'mylog/' ;
然后在hive shell commend repair一下mlog表 识别表分区
将分区数据添加到metastore
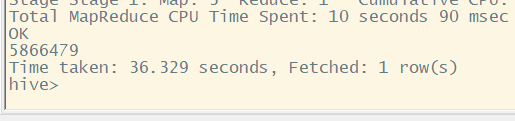
日志总行数 全部记录 5866479
1 select count (* ) from log;
独立ip数量 2387 1 select count (distinct (ip)) from log;
1 select ip,count (distinct (header)) c from log group by ip order by c desc ;# limit 10 ;
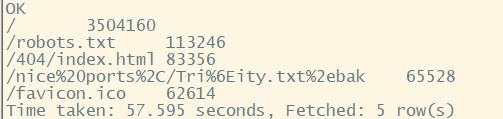
访问最多的url 1 select url,count (url) c from log group by url order by c desc ;
每个ip访问最多的url 1 select ip,url,count (url) c from log group by ip,url order by c desc ; #limit 300 ;
每小时访问量 指定分区 1 2 3 4 5 #不区分ip select substring (mtime,0 ,2 ),count (* ) from log where year = '2021' and month = '11' and day = '07' group by substring (mtime,0 ,2 ) limit 10 ;#每小时独立ip访问量 select substring (mtime,0 ,2 ),count (distinct (ip)) from log where year = '2021' and month = '11' and day = '07' group by substring (mtime,0 ,2 ) limit 10 ;#
编写shell脚本将每天的小时访问量数据导出到mysql
1 2 3 4 5 6 7 hive -e "create table qph as select substring(mtime,0,2),count(distinct(ip)) from log where year='2021' and month='11' and day='07' group by substring(mtime,0,2) limit 10;" sqoop export --connect jdbc:mysql://localhost:3306/loginfo --uername hadoop --password pwd --table daily --fields-terminated-by '\001' --export-dir 'user/hive/warehouse/log/qph' hive -e "drop table qph;"
添加定时任务 crontab -e
可视化数据 6.4样例
7.总结