load data local inpath '/usr/local/xxx' into table part1 partition(country='China'); #要指定分区
#修改分区的存储路径:(hdfs的路径必须是全路径)
1
alter table part1 partition(country='Vietnam') set location ‘hdfs://hadoop01:9000/user/hive/warehouse/brz.db/part1/country=Vietnam’
二级分区
1 2 3 4 5 6 7 8 9 10
create table if not exists part2( uid int, uname string, uage int ) PARTITIONED BY (year string,month string) row format delimited fields terminated by ','; # 导入多分区 load data local inpath '/usr/local/xxx' into table part1 partition(year='2018',month='09');
增加分区
1
alter table part1 add partition(country='india') partition(country='korea') partition(country='America')
动态分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
#动态分区的属性: set hive.exec.dynamic.partition=true;//(true/false) set hive.exec.dynamic.partition.mode=strict;//(strict/nonstrict) #至少有一个静态的值 set hive.exec.dynamic.partitions=1000;//(分区最大数) set hive.exec.max.dynamic.partitions.pernode=100 #创建动态分区表 create table if not exists dt_part1( uid int, uname string, uage int ) PARTITIONED BY (year string,month string) row format delimited fields terminated by ',' ; #加载数据:(使用 insert into方式加载数据) insert into dy_part1 partition(year,month) select * from part_tmp ;
分桶
在分区下分桶,分桶使用表内字段
1 2 3 4 5 6 7
语法格式 CREATE TABLE test (<col_name> <data_type> [, <col_name> <data_type> ...])] [PARTITIONED BY ...] CLUSTERED BY (<col_name>) [SORTED BY (<col_name> [ASC|DESC] [, <col_name> [ASC|DESC]...])] INTO <num_buckets> BUCKETS
#装载数据 Load data to table inpath #插入数据 Insert into table emp partition(year=2021,month=10) select id,name from ept; #导出数据 #到hdfs Export table ept to ‘/hom/emp’; #Insert 导出 Insert overwrite local directory ‘path’ select * from emp; #到本地 Hfds dfs -get localpath #Hive shell 命令导出 Hive -e ‘select * from emp;’ > localpath #导入数据 Import table emp from path; #HQL查询 Case when Select name,salary, case Wehn salary <5000 then ‘low’ When salary >=5000 and salary <7000 then ‘middle’ Whne salary >=7000 then salary < 10000 then ‘high’ Else ‘vary high’ End as bracket from emp;
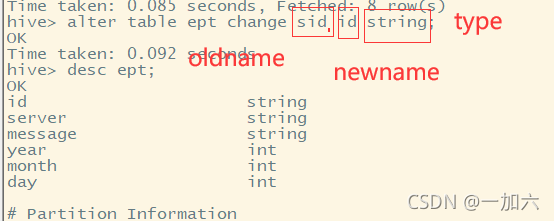
cast(value AS TYPE) ALTER TABLE employees CHANGE COLUMN salary salary STRING; SELECT name,salary FROM employees WHERE cast(salary AS FLOAT) < 100000.0;
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nostrict; set hive.exec.max.dynamic.partitions=100000; set hive.merge.smallfiles.avgsize=128000000; #128M set hive.merge.size.per.task=128000000;
将原表数据合并到临时表
1
insert overwrite table test select * from table;
创建备份目录将原表数据放进备份目录,将临时表数据迁移至原表目录
hive数据倾斜问题
核心解决方案时多段聚合,将第一次聚合时每个key加上随机数,对数据打散,在进行二次聚合。
group by distinct
进行group by 时形成 key val_list,当某些key重复数据较多时,就会产生数据倾斜
核心解决方案时多段聚合,将第一次聚合时每个key加上随机数,对数据打散,在进行二次聚合。
join导致的
找出on的字段重复
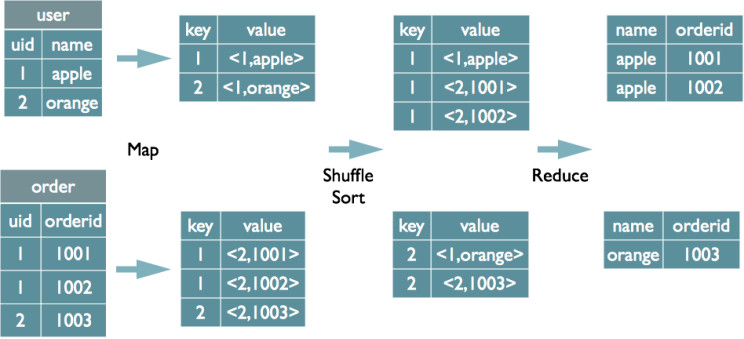
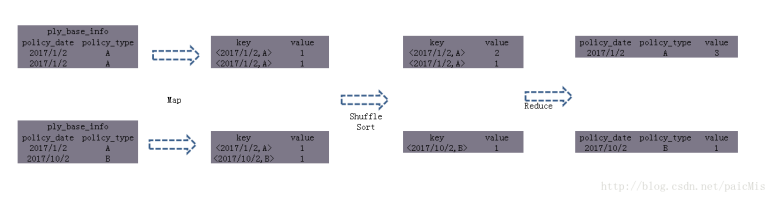
hive text 如何转换为mapreduce任务
1
select userid from user group by userid;
group by 的字段组合作为 map任务输出key的值,同时作为reduce得输入,在map阶段之后的分区、排序时reduce将相同的key放到一起来处理