
spark job的几种提交流程
standalone
集群启动后worker向master注册信息,
通过spark-submit提交任务时,在任务提交节点或Client启动driver,
在driver创建并初始化sparkContext对象,包含DAGScheduler和TaskScheduler,TaskScheduler与Master节点通讯申请注册Application,Master节点接收到Application的注册请求后,通过资源调度算法,在自己的集群的worker上启动Executor进程;启动的Executor也会反向注册到TaskScheduler上
DAGScheduler:负责把Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图),根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler;
所有task运行完成后,SparkContext向Master注销,释放资源;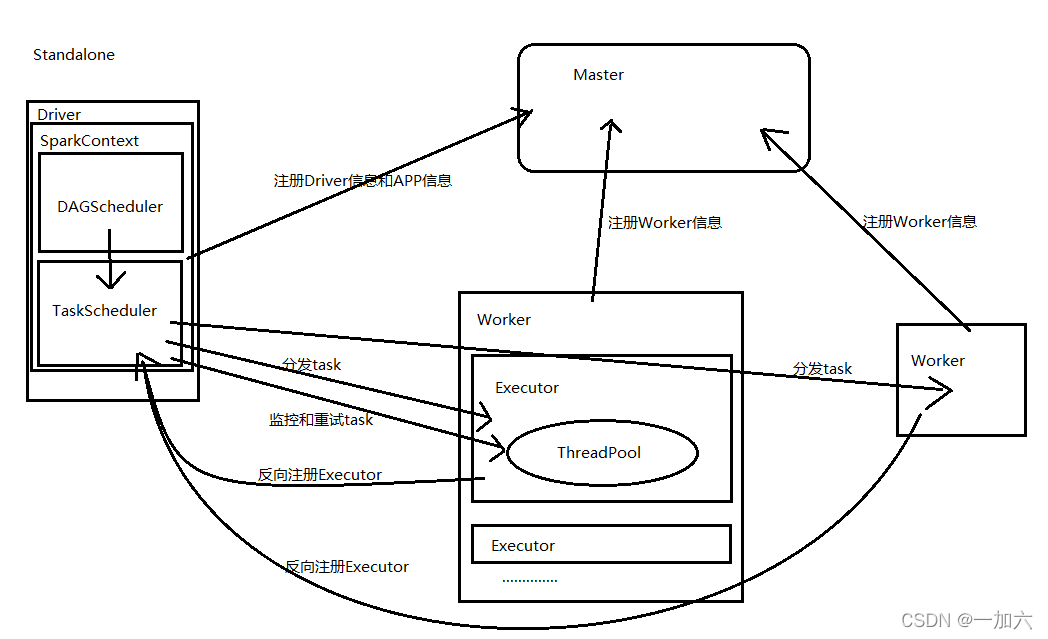
参考文章
spark on yarn
配置
在client节点配置中spark-env.sh添加Hadoop_HOME的配置目录即可提交yarn 任务,具体步骤如下:
1 | export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop |
注意client只需要有Spark的安装包即可提交任务,不需要其他配置(比如slaves)!!!
client
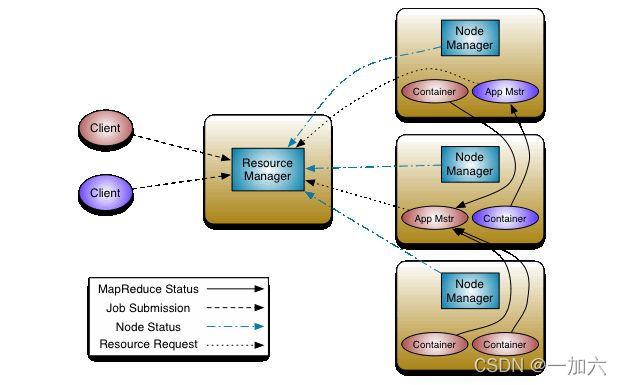
SparkContext在Client创建并实例化
1.client向ResouceManager申请启动ApplicationMaster,同时在SparkContext初始化中创建DAGScheduler和TaskScheduler
2.ResouceManager收到请求后,在一台NodeManager中启动第一个Container运行ApplicationMaster
3.Dirver中的SparkContext初始化完成后与ApplicationMaster建立通讯,ApplicationMaster向ResourceManager申请Application的资源
4.一旦ApplicationMaster申请到资源,便与之对应的NodeManager通讯,启动Executor,并把Executor信息反向注册给Dirver
5.Dirver分发task,并监控Executor的运行状态,负责重试失败的task
6.运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
1 | #当前目录 |
–class 是全限定类名
–master yarn 是指使用yarn管理
–deploy-mode client*cluster* client可以在提交任务的机器查看结果
cluster只能在yarn上看结果
–conf spark.driver.host=192.168.88.12 driver监听的主机名或者IP地址。就是提交任务机器的地址,这用于和executors以及独立的master通信接收结果
examples/jars/spark-examples_2.11-2.2.3.jar 运行的jar包
当我们测试一个demo如下图会为spark任务自动机器CPU、内存等资源
Cluster
1.client向ResouceManager申请启动ApplicationMaster,同时在SparkContext初始化中创建DAGScheduler和TaskScheduler
2.ResouceManager收到请求后,在一台NodeManager中启动第一个Container运行ApplicationMaster
3.Dirver中的SparkContext初始化完成后与ApplicationMaster建立通讯,ApplicationMaster向ResourceManager申请Application的资源
4.一旦ApplicationMaster申请到资源,便与之对应的NodeManager通讯,启动Executor,并把Executor信息反向注册给Dirver
5.Dirver分发task,并监控Executor的运行状态,负责重试失败的task
6.运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
Yarn-client和Yarn-cluster的区别:
yarn-cluster模式下,Dirver运行在ApplicationMaster中,负责申请资源并监控task运行状态和重试失败的task,当用户提交了作业之后就可以关掉client,作业会继续在yarn中运行;
yarn-client模式下,Dirver运行在本地客户端,client不能离开。



