
Spark学习记录
spark介绍
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集,具有以下特点:
1.运行速度快:Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
2.易用性好:Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
3.通用性强:Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理。
4.随处运行:Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算
Spark与Hadoop差异
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
最后,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
原文链接
spark安装
下载解压
下载安装包 解压到本地软件安装目录
spark-2.4.8.tgz
1 | cd /export/servers |
添加系统环境变量
1 | vi /etc/profile |
spark-shell
1 | spark-shell |

spark任务提交执行
standalone spark自主管理的集群模式
要配置spark安装目录下的slaves文件添加本地注意域名映射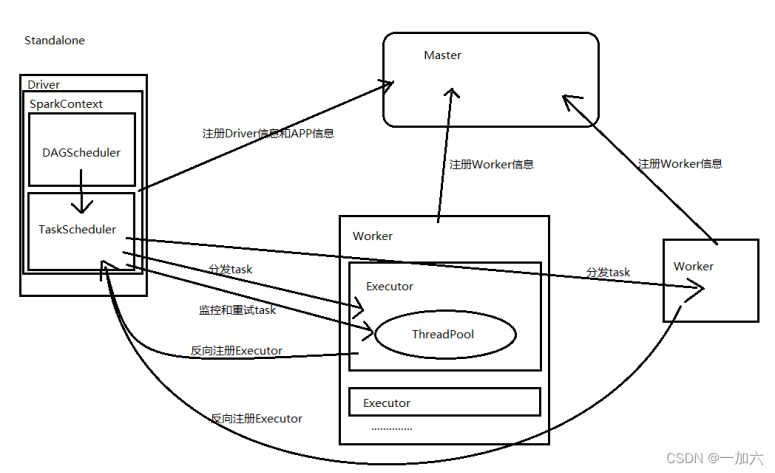
通过spark-submit提交任务时,在任务提交节点或Client启动driver,
在driver创建并初始化sparkContext对象包含DAGScheduler和TaskScheduler,
与master通信申请资源,master指派worker为其启动executor
生成job阶段,遇到行动算子生成一个job
DAGScheduler负责把Sparkjob转换成Stage的DAG(Directed Acyclic Graph有向无环图),根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler;
TaskScheduler与Master节点通讯申请注册Application,Master节点接收到Application的注册请求后,通过资源调度算法,在自己的集群的worker上启动Executor进程;启动的Executor也会反向注册到TaskScheduler上
所有task运行完成后,SparkContext向Master注销,释放资源;
Stage阶段划分
根据宽依赖窄依赖划分阶段,判断宽依赖和窄依赖的依据是是否进行shuffle操作,不需要shuffle的窄依赖分到一个阶段中间的RDD转换操作无需落地,而宽依赖需要shuffle的过程数据需要落地磁盘
spark on yarn 提交到hadoop的yarn集群执行
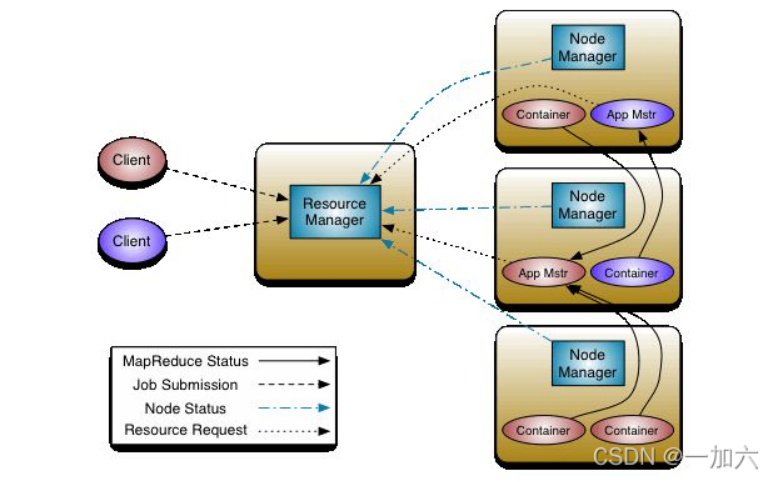
1.client向ResouceManager申请启动ApplicationMaster,同时在SparkContext初始化中创建DAGScheduler和TaskScheduler
2.ResouceManager收到请求后,在一台NodeManager中启动第一个Container运行ApplicationMaster
3.Dirver中的SparkContext初始化完成后与ApplicationMaster建立通讯,ApplicationMaster向ResourceManager申请Application的资源
4.一旦ApplicationMaster申请到资源,便与之对应的NodeManager通讯,启动Executor,并把Executor信息反向注册给Dirver
5.Dirver分发task,并监控Executor的运行状态,负责重试失败的task
6.运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
spark的模块
spark Core
###RDD
Spark提供的主要抽象是弹性分布式数据集(RDD),它是跨集群节点分区的元素集合,可以并行操作.
RDD特点:
- 1.它是在集群节点上的不可变的、已分区的集合对象;
- 2.通过并行转换的方式来创建(如 Map、 filter、join 等);
- 3.失败自动重建;
- 4.可以控制存储级别(内存、磁盘等)来进行重用;
- 5.必须是可序列化的;
- 6.是静态类型的(只读)。
RDD操作函数
RDD的操作函数主要分为2种类型行动算子(Transformation)和转换算子(Action).
可以对RDD进行函数操作,当你对一个RDD进行了操作,那么结果将会是一个新的RDD
Transformation操作不是马上提交Spark集群执行,Spark在遇到 Transformation操作时只会记录需要这样的操作,并不会去执行,需要等到有Action 操作的时候才会真正启动计算过程进行计算.
针对每个 Action,Spark 会生成一个Job, 从数据的创建开始,经过 Transformation, 结尾是 Action 操作.
这些操作对应形成一个有向无环图(DAG),形成 DAG 的先决条件是最后的函数操作是一个Action.
DAG stage 划分依据
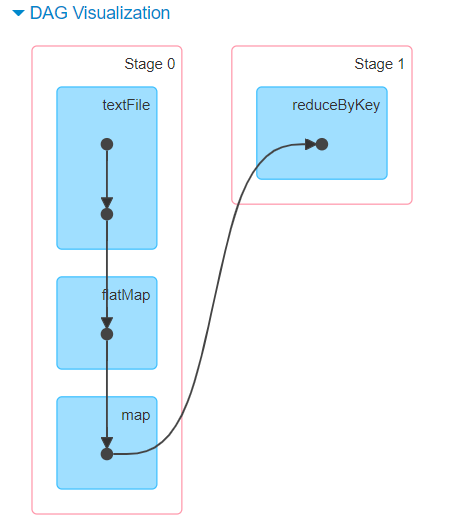
spark dagscheduler将任务划分stage,shuffle是划分DAG中stage 的标识,同时影响Spark执行速度的关键步骤.
RDD 的 Transformation 函数中,又分为窄依赖(narrow dependency)和宽依赖(wide dependency)的操作.
窄依赖跟宽依赖的区别是是否发生 shuffle(洗牌) 操作.宽依赖会发生 shuffle 操作.
窄依赖是子 RDD的各个分片(partition)不依赖于其他分片,能够独立计算得到结果,
宽依赖指子 RDD 的各个分片会依赖于父RDD 的多个分片,所以会造成父 RDD 的各个分片在集群中重新分片
shuffle优化
shuffle涉及网络传输和磁盘io,非常消耗资源 因此需要对shuffle优化
一是如果可以避免shuffle则不选择涉及shuffle的算子
rdd.groupByKey().mapValues(_ .sum) 与 rdd.reduceByKey(_ + _) 执行的结果是一样的,但是前者需要把全部的数据通过网络传递一遍,而后者只需要根据每个 key 局部的 partition 累积结果,在 shuffle 的之后把局部的累积值相加后得到结果.
缓存机制 cache persist
Spark中对于一个RDD执行多次算子(函数操作)的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。
对于这种情况,可对多次使用的RDD进行持久化。
cache 是使用的默认缓存选项,一般默认为Memoryonly(内存中缓存),
persist 则可以在缓存的时候选择任意一种缓存类型.事实上,cache内部调用的是默认的persist.persist可选择的方式很多缓存到磁盘或是内存磁盘组合缓存等
spark常用算子
转换算子(Transformations)
| Transformations | Description |
|---|---|
| map(func) | 通过函数func传递源的每个元素,返回一个新的分布式数据集。 |
| filter(func) | 过滤数据,通过选择func返回true的源元素返回一个新的数据集。 |
| flatMap(func) | 与map类似,但是每个输入项都可以映射到0个或更多的输出项(因此func应该返回一个Seq而不是单个项)。展平 多个集合 汇总成一个集合 |
| mapPartitions(func) | 与map类似,但在RDD的每个分区(块)上分别运行,因此在类型为T的RDD上运行时,func必须是Iterator => Iterator |
| mapPartitionsWithIndex(func) | 与mapPartitions类似,但也为func提供了一个表示分区索引的整数值,因此func必须是类型(Int, Iterator) => Iterator时,类型为T的RDD。 |
| sample(withReplacement, fraction, seed) | 使用给定的随机数生成器种子,对数据的一小部分进行抽样,无论是否进行替换。 |
| union(otherDataset) | 合并,返回一个新数据集,其中包含源数据集中的元素和参数的并集。 |
| intersection(otherDataset) | 交集,返回一个新的RDD,其中包含源数据集中的元素和参数的交集。 |
| distinct([numPartitions])) | 去重,返回包含源数据集的不同元素的新数据集。 |
| groupByKey([numPartitions]) | 当对一个(K, V)对的数据集调用时,返回一个(K,可迭代)对的数据集。注意:如果您要对每个键进行分组以执行聚合(比如求和或平均),那么使用reduceByKey或aggregateByKey将产生更好的性能。注意:默认情况下,输出中的并行级别取决于父RDD的分区数量。您可以传递一个可选的numPartitions参数来设置不同数量的任务。 |
| reduceByKey(func, [numPartitions]) | 在(K,V)对的数据集上调用时,返回一个(K,V)对的数据集,其中每个键的值使用给定的reduce函数func进行聚合,该函数的类型必须是(V,V)=>V。与groupByKey一样,reduce任务的数量可以通过可选的第二个参数进行配置。 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | 当对一个(K, V)对的数据集调用时,返回一个(K, U)对的数据集,其中每个键的值使用给定的combine函数和一个中立的“零”值进行聚合。允许不同于输入值类型的聚合值类型,同时避免不必要的分配。与groupByKey类似,reduce任务的数量可以通过第二个可选参数进行配置。 |
| sortByKey([ascending], [numPartitions]) | 当对一个(K, V)对的数据集(K, V)调用时,K实现有序,返回一个(K, V)对的数据集,按键序升序或降序排序,如布尔升序参数中指定的那样。 |
| join(otherDataset, [numPartitions]) | 当对类型(K, V)和(K, W)的数据集调用时,返回一个(K, (V, W))对的数据集,其中包含每个键的所有元素对。通过leftOuterJoin、right touterjoin和fullOuterJoin来支持外部连接。 |
| cogroup(otherDataset, [numPartitions]) | 当对类型(K, V)和(K, W)的数据集调用时,返回一个元组(K, (Iterable, Iterable))的数据集。这个操作也称为groupWith。 |
| cartesian(otherDataset) | 当对T和U类型的数据集调用时,返回一个(T, U)对的数据集(所有元素对)。 |
| pipe(command, [envVars]) | 通过shell命令(例如Perl或bash脚本)管道传输RDD的每个分区。RDD元素被写入到进程的stdin中,并以字符串的RDD形式返回到它的stdout中的行输出。 |
| coalesce(numPartitions) | 将RDD中的分区数减少到numPartitions。用于筛选大型数据集后更有效地运行操作。 |
| repartition(numPartitions) | 随机重组RDD中的数据,创建更多或更少的分区,并在这些分区之间进行平衡。这总是在网络上对所有数据进行无序处理。 |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的分区器重新分区RDD,并在每个结果分区中按关键字对记录进行排序。这比在每个分区内调用重新分区然后进行排序更有效,因为它可以将排序向下推到无序处理机制中。 |
行动算子(Actions)
行动算子从功能上来说作为一个触发器,会触发提交整个作业并开始执行。从代码上来说,它与转换算子的最大不同之处在于:转换算子返回的还是 RDD,行动算子返回的是非 RDD 类型的值,如整数,或者根本没有返回值。
| Actions | Description |
|---|---|
| reduce(func) | 使用函数func(接受两个参数并返回一个)聚合数据集的元素。函数应该是可交换的和相联的,从而可以并行计算 |
| collect() | 在驱动程序中将数据集的所有元素作为数组返回。这通常在过滤器或其他返回足够小的数据子集的操作之后有用。 |
| count() | 返回数据集中元素的数量。 |
| first() | 返回数据集的第一个元素(类似于take(1))。 |
| take(n) | 返回一个包含数据集前n个元素的数组。 |
| takeSample(withReplacement, num, [seed]) | 返回数据集num元素的随机样本数组,可选地预先指定随机数生成器种子,是否进行替换。 |
| takeOrdered(n, [ordering]) | 使用自然顺序或自定义比较器返回RDD的前n个元素。 |
| saveAsTextFile(path) | 将数据集的元素作为文本文件(或一组文本文件)写入本地文件系统、HDFS或任何其他hadoop支持的文件系统的给定目录中。Spark将对每个元素调用toString,将其转换为文件中的一行文本。 |
| saveAsSequenceFile(path)(Java and Scala) | 在本地文件系统、HDFS或任何其他Hadoop支持的文件系统的给定路径中,将数据集的元素作为Hadoop序列文件编写。这在实现Hadoop可写接口的键值对RDDs上可用。在Scala中,它还可以用于隐式转换为可写的类型(Spark包括基本类型的转换,如Int、Double、String等)。 |
| saveAsObjectFile(path)(Java and Scala) | 使用Java序列化以简单的格式编写数据集的元素,然后可以使用SparkContext.objectFile()加载这些元素。 |
| countByKey() | 只在类型(K, V)的RDDs上可用。返回一个(K, Int)对的hashmap,并记录每个键的计数。 |
| foreach(func) | 对数据集的每个元素运行函数func。这通常是为了避免副作用,如更新累加器或与外部存储系统交互。注意:在foreach()之外修改除累加器以外的变量可能会导致未定义的行为。有关更多详细信息,请参见理解闭包。 |
RDD缓存
缓存是迭代算法和快速交互式使用的关键工具。第一次在操作中计算它时,它将保存在节点上的内存中。Spark的缓存是容错的 - 如果RDD的任何分区丢失,它将使用最初创建它的转换自动重新计算。persist() cache()
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they’re needed. This is the default level. |
| MEMORY_AND_DISK | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don’t fit on disk, and read them from there when they’re needed. |
| MEMORY_ONLY_SER (Java and Scala) | Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
| MEMORY_AND_DISK_SER (Java and Scala) | Similar to MEMORY_ONLY_SER, but spill partitions that don’t fit in memory to disk instead of recomputing them on the fly each time they’re needed. |
| DISK_ONLY | Store the RDD partitions only on disk. |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | Same as the levels above, but replicate each partition on two cluster nodes. |
| OFF_HEAP (experimental) | Similar to MEMORY_ONLY_SER, but store the data in off-heap memory. This requires off-heap memory to be enabled. |
unpersist()
广播变量
1 | scala> val broadcastVar = sc.broadcast(Array(1, 2, 3)) |
累加器
1 | scala> val accum = sc.longAccumulator("My Accumulator") |
spark SQL
SparkSession中所有功能的入口点是SparkSession类.使用:SparkSessionSparkSession.builder()创建SparkSession对象
1 | import org.apache.spark.sql.SparkSession |
创建dataframes
1 | val df = spark.read.json("examples/src/main/resources/people.json") |
UDF和UDAF
UDF用户自定义非聚合函数
UDAF用户自定义聚合操作函数
DataSources
load /save函数
1 | val usersDF = spark.read.load("examples/src/main/resources/users.parquet") |
format
1 | val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json") |
1 | val peopleDFCsv = spark.read.format("csv") |
Save Modes
| Scala/Java | Any Language | Meaning |
|---|---|---|
SaveMode.ErrorIfExists (default) |
erroror errorifexists(default) | When saving a DataFrame to a data source, if data already exists, an exception is expected to be thrown. |
SaveMode.Append |
append | When saving a DataFrame to a data source, if data/table already exists, contents of the DataFrame are expected to be appended to existing data. |
| SaveMode.Overwrite | overwrite | Overwrite mode means that when saving a DataFrame to a data source, if data/table already exists, existing data is expected to be overwritten by the contents of the DataFrame. |
| SaveMode.Ignore | ignore | Ignore mode means that when saving a DataFrame to a data source, if data already exists, the save operation is expected not to save the contents of the DataFrame and not to change the existing data. This is similar to a CREATE TABLE IF NOT EXISTS in SQL. |
JSON file
1 | // Primitive types (Int, String, etc) and Product types (case classes) encoders are |
hive 表
通过将 中的 (对于安全配置)和(对于 HDFS 配置)文件,可以完成 Hive 的配置。hive-site.xml``core-site.xml``hdfs-site.xml``conf/
1 | import java.io.File |
JDBC TO OTHER Databases
| Property Name | Meaning |
|---|---|
url |
The JDBC URL to connect to. The source-specific connection properties may be specified in the URL. e.g., jdbc:postgresql://localhost/test?user=fred&password=secret |
dbtable |
The JDBC table that should be read from or written into. Note that when using it in the read path anything that is valid in a FROM clause of a SQL query can be used. For example, instead of a full table you could also use a subquery in parentheses. It is not allowed to specify dbtable and query options at the same time. |
query |
A query that will be used to read data into Spark. The specified query will be parenthesized and used as a subquery in the FROM clause. Spark will also assign an alias to the subquery clause. As an example, spark will issue a query of the following form to the JDBC Source. SELECT <columns> FROM (<user_specified_query>) spark_gen_alias Below are couple of restrictions while using this option. It is not allowed to specify dbtable and query options at the same time.It is not allowed to specify query and partitionColumn options at the same time. When specifying partitionColumn option is required, the subquery can be specified using dbtable option instead and partition columns can be qualified using the subquery alias provided as part of dbtable. Example: spark.read.format("jdbc").option("url", jdbcUrl).option("query", "select c1, c2 from t1").load() |
driver |
The class name of the JDBC driver to use to connect to this URL. |
partitionColumn, lowerBound, upperBound |
These options must all be specified if any of them is specified. In addition, numPartitions must be specified. They describe how to partition the table when reading in parallel from multiple workers. partitionColumn must be a numeric, date, or timestamp column from the table in question. Notice that lowerBound and upperBound are just used to decide the partition stride, not for filtering the rows in table. So all rows in the table will be partitioned and returned. This option applies only to reading. |
numPartitions |
The maximum number of partitions that can be used for parallelism in table reading and writing. This also determines the maximum number of concurrent JDBC connections. If the number of partitions to write exceeds this limit, we decrease it to this limit by calling coalesce(numPartitions) before writing. |
queryTimeout |
The number of seconds the driver will wait for a Statement object to execute to the given number of seconds. Zero means there is no limit. In the write path, this option depends on how JDBC drivers implement the API setQueryTimeout, e.g., the h2 JDBC driver checks the timeout of each query instead of an entire JDBC batch. It defaults to 0. |
fetchsize |
The JDBC fetch size, which determines how many rows to fetch per round trip. This can help performance on JDBC drivers which default to low fetch size (eg. Oracle with 10 rows). This option applies only to reading. |
batchsize |
The JDBC batch size, which determines how many rows to insert per round trip. This can help performance on JDBC drivers. This option applies only to writing. It defaults to 1000. |
isolationLevel |
The transaction isolation level, which applies to current connection. It can be one of NONE, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, or SERIALIZABLE, corresponding to standard transaction isolation levels defined by JDBC’s Connection object, with default of READ_UNCOMMITTED. This option applies only to writing. Please refer the documentation in java.sql.Connection. |
sessionInitStatement |
After each database session is opened to the remote DB and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block). Use this to implement session initialization code. Example: option("sessionInitStatement", """BEGIN execute immediate 'alter session set "_serial_direct_read"=true'; END;""") |
truncate |
This is a JDBC writer related option. When SaveMode.Overwrite is enabled, this option causes Spark to truncate an existing table instead of dropping and recreating it. This can be more efficient, and prevents the table metadata (e.g., indices) from being removed. However, it will not work in some cases, such as when the new data has a different schema. It defaults to false. This option applies only to writing. |
cascadeTruncate |
This is a JDBC writer related option. If enabled and supported by the JDBC database (PostgreSQL and Oracle at the moment), this options allows execution of a TRUNCATE TABLE t CASCADE (in the case of PostgreSQL a TRUNCATE TABLE ONLY t CASCADE is executed to prevent inadvertently truncating descendant tables). This will affect other tables, and thus should be used with care. This option applies only to writing. It defaults to the default cascading truncate behaviour of the JDBC database in question, specified in the isCascadeTruncate in each JDBCDialect. |
createTableOptions |
This is a JDBC writer related option. If specified, this option allows setting of database-specific table and partition options when creating a table (e.g., CREATE TABLE t (name string) ENGINE=InnoDB.). This option applies only to writing. |
createTableColumnTypes |
The database column data types to use instead of the defaults, when creating the table. Data type information should be specified in the same format as CREATE TABLE columns syntax (e.g: "name CHAR(64), comments VARCHAR(1024)"). The specified types should be valid spark sql data types. This option applies only to writing. |
customSchema |
The custom schema to use for reading data from JDBC connectors. For example, "id DECIMAL(38, 0), name STRING". You can also specify partial fields, and the others use the default type mapping. For example, "id DECIMAL(38, 0)". The column names should be identical to the corresponding column names of JDBC table. Users can specify the corresponding data types of Spark SQL instead of using the defaults. This option applies only to reading. |
pushDownPredicate |
The option to enable or disable predicate push-down into the JDBC data source. The default value is true, in which case Spark will push down filters to the JDBC data source as much as possible. Otherwise, if set to false, no filter will be pushed down to the JDBC data source and thus all filters will be handled by Spark. Predicate push-down is usually turned off when the predicate filtering is performed faster by Spark than by the JDBC data source. |
1 | // Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods |
性能调优
缓存内存中的数据
Spark SQL 可以通过调用 或 使用 内存中列式格式 来缓存表。然后,Spark SQL 将仅扫描所需的列,并将自动调整压缩,以最大程度地减少内存使用量和 GC 压力。您可以调用以从内存中删除该表。
1 | spark.catalog.cacheTable("tableName") |
其他配置选项
以下选项还可用于优化查询执行的性能。这些选项可能会在将来的版本中弃用,因为会自动执行更多优化。
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.files.maxPartitionBytes |
134217728 (128 MB) | The maximum number of bytes to pack into a single partition when reading files. |
spark.sql.files.openCostInBytes |
4194304 (4 MB) | The estimated cost to open a file, measured by the number of bytes could be scanned in the same time. This is used when putting multiple files into a partition. It is better to over-estimated, then the partitions with small files will be faster than partitions with bigger files (which is scheduled first). |
spark.sql.broadcastTimeout |
300 | Timeout in seconds for the broadcast wait time in broadcast joins |
spark.sql.autoBroadcastJoinThreshold |
10485760 (10 MB) | Configures the maximum size in bytes for a table that will be broadcast to all worker nodes when performing a join. By setting this value to -1 broadcasting can be disabled. Note that currently statistics are only supported for Hive Metastore tables where the command ANALYZE TABLE <tableName> COMPUTE STATISTICS noscan has been run. |
spark.sql.shuffle.partitions |
200 | Configures the number of partitions to use when shuffling data for joins or aggregations. |
SQL 查询的使用广播变量
1 | import org.apache.spark.sql.functions.broadcast |
与 Apache Hive 的兼容性
支持的配置单元功能
Spark SQL 支持绝大多数 Hive 功能,例如:
- Hive 查询语句,包括:
SELECTGROUP BYORDER BYCLUSTER BYSORT BY
- 所有 Hive 运算符,包括:
- 关系运算符 (, , , , , , , , 等)
=``⇔``==``<>``<``>``>=``<= - 算术运算符(、、、、等)
+``-``*``/``% - 逻辑运算符(、、、、等)
AND``&&``OR``|| - 复杂类型构造函数
- 数学函数(、、、等)
sign``ln``cos - 字符串函数(、、、等)
instr``length``printf
- 关系运算符 (, , , , , , , , 等)
- 用户定义函数 (UDF)
- 用户定义的聚合函数 (UDAF)
- 用户定义的序列化格式 (SerDes)
- 窗口函数
- 加入
JOIN{LEFT|RIGHT|FULL} OUTER JOINLEFT SEMI JOINCROSS JOIN
- 工会
- 子查询
SELECT col FROM ( SELECT a + b AS col from t1) t2
- 采样
- 解释
- 分区表,包括动态分区插入
- 视图
- 所有 Hive DDL 函数,包括:
CREATE TABLECREATE TABLE AS SELECTALTER TABLE
- 大多数 Hive 数据类型,包括:
TINYINTSMALLINTINTBIGINTBOOLEANFLOATDOUBLESTRINGBINARYTIMESTAMPDATEARRAY<>MAP<>STRUCT<>
structure treaming
example
1 | // Create DataFrame representing the stream of input lines from connection to localhost:9999 |
数据源
| Source | Options | Fault-tolerant | Notes |
| File source | path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to process the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to true, the following files would be considered as the same file, because their filenames, “dataset.txt”, are the same: “file:///dataset.txt” “s3://a/dataset.txt” “s3n://a/b/dataset.txt” “s3a://a/b/c/dataset.txt” maxFileAge: Maximum age of a file that can be found in this directory, before it is ignored. For the first batch all files will be considered valid. If latestFirst is set to true and maxFilesPerTrigger is set, then this parameter will be ignored, because old files that are valid, and should be processed, may be ignored. The max age is specified with respect to the timestamp of the latest file, and not the timestamp of the current system.(default: 1 week) cleanSource: option to clean up completed files after processing. Available options are “archive”, “delete”, “off”. If the option is not provided, the default value is “off”. When “archive” is provided, additional option sourceArchiveDir must be provided as well. The value of “sourceArchiveDir” must not match with source pattern in depth (the number of directories from the root directory), where the depth is minimum of depth on both paths. This will ensure archived files are never included as new source files. For example, suppose you provide ‘/hello?/spark/‘ as source pattern, ‘/hello1/spark/archive/dir’ cannot be used as the value of “sourceArchiveDir”, as ‘/hello?/spark/‘ and ‘/hello1/spark/archive’ will be matched. ‘/hello1/spark’ cannot be also used as the value of “sourceArchiveDir”, as ‘/hello?/spark’ and ‘/hello1/spark’ will be matched. ‘/archived/here’ would be OK as it doesn’t match. Spark will move source files respecting their own path. For example, if the path of source file is /a/b/dataset.txt and the path of archive directory is /archived/here, file will be moved to /archived/here/a/b/dataset.txt. NOTE: Both archiving (via moving) or deleting completed files will introduce overhead (slow down, even if it’s happening in separate thread) in each micro-batch, so you need to understand the cost for each operation in your file system before enabling this option. On the other hand, enabling this option will reduce the cost to list source files which can be an expensive operation. Number of threads used in completed file cleaner can be configured withspark.sql.streaming.fileSource.cleaner.numThreads (default: 1). NOTE 2: The source path should not be used from multiple sources or queries when enabling this option. Similarly, you must ensure the source path doesn’t match to any files in output directory of file stream sink. NOTE 3: Both delete and move actions are best effort. Failing to delete or move files will not fail the streaming query. Spark may not clean up some source files in some circumstances - e.g. the application doesn’t shut down gracefully, too many files are queued to clean up. For file-format-specific options, see the related methods in DataStreamReader (Scala/Java/Python/R). E.g. for “parquet” format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for “parquet”, see Parquet configuration section. |
Yes | Supports glob paths, but does not support multiple comma-separated paths/globs. |
| Socket Source | host: host to connect to, must be specified port: port to connect to, must be specified |
No | |
| Rate Source | rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second. rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark’s default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed. |
Yes | |
| Kafka Source | See the Kafka Integration Guide. | Yes |
Output Sinks
There are a few types of built-in output sinks.
- File sink - Stores the output to a directory.
1 | writeStream |
- Kafka sink - Stores the output to one or more topics in Kafka.
1 | writeStream |
- Foreach sink - Runs arbitrary computation on the records in the output. See later in the section for more details.
1 | writeStream |
- Console sink (for debugging) - Prints the output to the console/stdout every time there is a trigger. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory after every trigger.
1 | writeStream |
- Memory sink (for debugging) - The output is stored in memory as an in-memory table. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory. Hence, use it with caution.
1 | writeStream |
Some sinks are not fault-tolerant because they do not guarantee persistence of the output and are meant for debugging purposes only. See the earlier section on fault-tolerance semantics. Here are the details of all the sinks in Spark.
| Sink | Supported Output Modes | Options | Fault-tolerant | Notes |
|---|---|---|---|---|
| File Sink | Append | path: path to the output directory, must be specified. retention: time to live (TTL) for output files. Output files which batches were committed older than TTL will be eventually excluded in metadata log. This means reader queries which read the sink’s output directory may not process them. You can provide the value as string format of the time. (like “12h”, “7d”, etc.) By default it’s disabled. For file-format-specific options, see the related methods in DataFrameWriter (Scala/Java/Python/R). E.g. for “parquet” format options see DataFrameWriter.parquet() |
Yes (exactly-once) | Supports writes to partitioned tables. Partitioning by time may be useful. |
| Kafka Sink | Append, Update, Complete | See the Kafka Integration Guide | Yes (at-least-once) | More details in the Kafka Integration Guide |
| Foreach Sink | Append, Update, Complete | None | Yes (at-least-once) | More details in the next section |
| ForeachBatch Sink | Append, Update, Complete | None | Depends on the implementation | More details in the next section |
| Console Sink | Append, Update, Complete | numRows: Number of rows to print every trigger (default: 20) truncate: Whether to truncate the output if too long (default: true) |
No | |
| Memory Sink | Append, Complete | None | No. But in Complete Mode, restarted query will recreate the full table. | Table name is the query name. |
Triggers 触发器
| Fixed interval micro-batches | 查询将以微批处理模式执行,其中微批处理将按用户指定的时间间隔启动。如果前一个微批处理在间隔内完成,则引擎将等到间隔结束,然后再启动下一个微批次。如果前一个微批处理花费的时间超过完成间隔的时间(即,如果错过了间隔边界),则下一个微批处理将在前一个微批处理完成后立即启动(即,它不会等待下一个间隔边界)。如果没有新数据可用,则不会启动任何微批处理。 |
|---|---|
| One-time micro-batch | 查询将仅执行一个微批处理来处理所有可用数据,然后自行停止。这在您希望定期启动群集、处理自上一个周期以来可用的所有内容,然后关闭群集的情况下非常有用。在某些情况下,这可能会节省大量成本。 |
| Continuous with fixed checkpoint interval (experimental) | 查询将在新的低延迟连续处理模式下执行。在下面的”连续处理”部分中阅读有关此内容的更多信息。 |
sparkstreaming

在内部,它的工作方式如下。Spark 流接收实时输入数据流并将数据划分为批次,然后由 Spark 引擎处理这些批处理,以批量生成最终的结果流。

A Quick Example
1 | import org.apache.spark._ |
1 | # TERMINAL 1: # Running Netcat $ nc -lk 9999 hello world |
1 | # TERMINAL 2: RUNNING NetworkWordCount |
基本概念
引入sparkstreaming
1 | <dependency> |
要从 Spark Streaming 核心 API 中不存在的 Kafka 和 Kinesis 等源引入数据,必须将相应的项目添加到依赖项中。例如,一些常见的如下。spark-streaming-xyz_2.12
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-10_2.12 |
| Kinesis | spark-streaming-kinesis-asl_2.12 [Amazon Software License] |
初始化spark上下文
1 | import org.apache.spark._ |
还可以从现有对象创建对象。StreamingContext``SparkContext
1 | import org.apache.spark.streaming._ |
定义上下文后,必须执行以下操作。
- 通过创建输入 DStream 来定义输入源。
- 通过将转换和输出操作应用于 DStream 来定义流式计算。
- 开始接收数据并使用 进行处理。
streamingContext.start() - 使用 等待停止处理(手动或由于任何错误)。
streamingContext.awaitTermination() - 可以使用 手动停止处理。
streamingContext.stop()
要记住的要点:
- 启动上下文后,无法设置或向其添加新的流式计算。
- 一旦上下文停止,就无法重新启动。
- 一个 JVM 中只能同时激活一个流式流上下文。
- StreamingContext 上的 stop() 也会停止 SparkContext。若要仅停止流式处理上下文,请将 called 的可选参数设置为 false。
stop()``stopSparkContext - SparkContext 可以重新用于创建多个 StreamingContext,只要在创建下一个 StreamingContext 之前停止(不停止 SparkContext)即可。
DStream
DStream 是 Spark 流提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象(有关详细信息,请参阅Spark编程指南)。DStream 中的每个 RDD 都包含特定时间间隔的数据

文件流
1 | streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory) |
如何监视目录
Spark 流式处理将监视该目录并处理在该目录中创建的任何文件。dataDirectory
- 可以监视一个简单的目录,例如 。直接位于此类路径下的所有文件都将在被发现时进行处理。
"hdfs://namenode:8040/logs/" - 可以提供 POSIX glob 模式,例如 。在这里,DStream 将包含目录中与模式匹配的所有文件。也就是说:它是目录的模式,而不是目录中的文件的模式。
"hdfs://namenode:8040/logs/2017/*" - 所有文件必须采用相同的数据格式。
- 文件根据其修改时间(而不是其创建时间)被视为时间段的一部分。
- 处理后,在当前窗口中对文件所做的更改将不会导致重新读取该文件。也就是说:更新将被忽略。
- 目录下的文件越多,扫描更改所需的时间就越长,即使没有修改任何文件也是如此。
- 如果使用通配符来标识目录(例如 ),则重命名整个目录以匹配路径会将该目录添加到受监视目录列表中。只有目录中修改时间在当前窗口内的文件才会包含在流中。
"hdfs://namenode:8040/logs/2016-*" - 调用
FileSystem.setTimes() 来修复时间戳是一种在以后的窗口中选取文件的方法,即使其内容没有更改。
文件写入时不要监控
”完整”文件系统(如 HDFS)倾向于在创建输出流后立即设置其文件的修改时间。当文件被打开时,甚至在数据完全写入之前,它也可能包含在 - 中,之后将忽略同一窗口中对文件的更新。也就是说:可能会错过更改,并且从流中省略数据。
要确保在窗口中选取更改,请将文件写入不受监视的目录,然后在输出流关闭后立即将其重命名为目标目录。如果重命名的文件在创建过程中出现在扫描的目标目录中,则将选取新数据。
DStream 上的转换
| Transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new “state” DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
UpdateStateByKey 操作
该操作允许您保持任意状态,同时不断使用新信息对其进行更新。要使用它,您必须执行两个步骤。updateStateByKey
- 定义状态 - 状态可以是任意数据类型。
- 定义状态更新函数 - 使用函数指定如何使用以前的状态和输入流中的新值来更新状态。
在每个批次中,Spark 都会对所有现有密钥应用状态更新功能,无论它们是否在批处理中具有新数据。如果更新函数返回,则键值对将被淘汰。None
转换操作
该操作(及其变体,如)允许在DStream上应用任意RDD到RDD函数。它可用于应用 DStream API 中未公开的任何 RDD 操作。例如,将数据流中的每个批与另一个数据集联接的功能不会直接在 DStream API 中公开。但是,您可以轻松地使用它来执行此操作。这带来了非常强大的可能性。例如,可以通过将输入数据流与预先计算的垃圾邮件信息(也可能是由Spark生成的)连接起来,然后基于它进行过滤来执行实时数据清理。
窗口操作
Spark 流式处理还提供窗口化计算,允许您在滑动的数据窗口上应用转换。下图说明了此滑动窗口。
如图所示,每次窗口在源 DStream 上滑动时,落在窗口内的源 RDD 都会被组合并操作,以生成窗口 DStream 的 RDD。在此特定情况下,该操作应用于数据的最近 3 个时间单位,并按 2 个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
- 窗口长度 - 窗口的持续时间(图中为 3)。
- 滑动间隔 - 执行窗口操作的时间间隔(图中为 2)。
这两个参数必须是源 DStream 的批处理间隔的倍数(图中为 1)。
让我们通过一个示例来说明窗口操作。假设,您希望通过每 10 秒生成一次数据的最后 30 秒的字数统计来扩展前面的示例。为此,我们必须在数据的最后 30 秒内对 DStream 上应用该操作。这是使用 操作完成的。reduceByKey``pairs``(word, 1)``reduceByKeyAndWindow
1 | // Reduce last 30 seconds of data, every 10 seconds |
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enters the sliding window, and “inverse reducing” the old data that leaves the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable only to “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that checkpointing must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
联接操作
最后,值得强调的是,您可以在Spark Streaming中轻松执行不同类型的联接。
流-流联接
流可以很容易地与其他流连接。
1 | val stream1: DStream[String, String] = ... |
在每个批处理间隔中,生成的 RDD 将与 生成的 RDD 合并。也可以在流的窗口上进行联接通常非常有用。这也很容易。
1 | val windowedStream1 = stream1.window(Seconds(20)) |
DStream 上的输出操作
输出操作允许将 DStream 的数据推送到外部系统,如数据库或文件系统。由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有 DStream 转换的实际执行(类似于 RDD 的操作)。目前,定义了以下输出操作:
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream’s contents as text files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream’s contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream’s contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
缓存/持久性
与RDD类似,DStreams还允许开发人员将流的数据保存在内存中。也就是说,在 DStream 上使用该方法将自动在内存中保留该 DStream 的每个 RDD。如果 DStream 中的数据将被多次计算(例如,对同一数据执行多个操作),这将非常有用。对于基于窗口的操作(如 和)和基于状态的操作(如 ),这是隐式正确的。因此,由基于窗口的操作生成的 DStream 会自动保留在内存中,而无需开发人员调用 。persist()``reduceByWindow``reduceByKeyAndWindow``updateStateByKey``persist()
对于通过网络接收数据的输入流(如 Kafka、套接字等),默认持久性级别设置为将数据复制到两个节点以实现容错。
请注意,与 RDD 不同,DStreams 的默认持久性级别将数据序列化在内存中。这将在性能调整部分中进一步讨论。有关不同持久性级别的详细信息,请参阅 Spark 编程指南。
检查点
流式处理应用程序必须全天候运行,因此必须能够灵活应对与应用程序逻辑无关的故障(例如,系统故障、JVM 崩溃等)。为了实现这一点,Spark 流需要将足够的信息检查点到容错存储系统,以便它可以从故障中恢复。有两种类型的数据需要检查点。
- 元数据检查点 - 将定义流式计算的信息保存到容错存储(如 HDFS)中。这用于从运行流式处理应用程序驱动程序的节点的故障中恢复(稍后将详细讨论)。元数据包括:
- 配置 - 用于创建流式处理应用程序的配置。
- DStream 操作 - 定义流式处理应用程序的 DStream 操作集。
- 不完整批处理 - 作业已排队但尚未完成的批处理。
- 数据检查点 - 将生成的RDD保存到可靠的存储中。这在某些跨多个批处理组合数据的有状态转换中是必需的。在此类转换中,生成的 RDD 依赖于先前批次的 RDD,这会导致依赖关系链的长度随时间不断增加。为了避免恢复时间的这种无限增加(与依赖关系链成正比),有状态转换的中间RDD定期通过检查点连接到可靠存储(例如HDFS)以切断依赖关系链。
总而言之,元数据检查点主要用于从驱动程序故障中恢复,而数据或 RDD 检查点对于使用有状态转换时,即使对于基本功能也是必需的。
何时启用检查点
必须为具有以下任一要求的应用程序启用检查点:
- 有状态转换的使用 - 如果在应用程序中使用或(具有反向函数),则必须提供检查点目录以允许定期 RDD 检查点。
updateStateByKey``reduceByKeyAndWindow - 从运行应用程序的驱动程序的故障中恢复 - 元数据检查点用于使用进度信息进行恢复。
请注意,无需启用检查点即可运行没有上述有状态转换的简单流式处理应用程序。在这种情况下,从驱动程序故障中恢复也将是部分的(一些已接收但未处理的数据可能会丢失)。这通常是可以接受的,许多以这种方式运行 Spark 流式处理应用程序。对非Hadoop环境的支持预计将来会得到改善。
如何配置检查点
可以通过在容错、可靠的文件系统(例如 HDFS、S3 等)中设置一个目录来启用检查点,检查点信息将保存到该文件系统中。这是通过使用 来完成的。这将允许您使用上述有状态转换。此外,如果要使应用程序从驱动程序故障中恢复,则应重写流式处理应用程序以具有以下行为。streamingContext.checkpoint(checkpointDirectory)
- 当程序首次启动时,它将创建一个新的StreamingContext,设置所有流,然后调用start()。
- 当程序在失败后重新启动时,它将从检查点目录中的检查点数据重新创建流式处理上下文。
部署应用程序
本节讨论部署 Spark 流式处理应用程序的步骤。
要求
若要运行 Spark 流式处理应用程序,需要具备以下条件。
- 具有集群管理器的集群 - 这是任何 Spark 应用程序的一般要求,在部署指南中进行了详细讨论。
- 打包应用程序 JAR - 您必须将流式处理应用程序编译为 JAR。如果使用
spark-submit 启动应用程序,则无需在 JAR 中提供 Spark 和 Spark 流式处理。但是,如果您的应用程序使用高级源(例如 Kafka),则必须将它们链接到的额外工件及其依赖项打包到用于部署应用程序的 JAR 中。例如,使用的应用程序必须在应用程序 JAR 中包含其所有可传递依赖项及其所有依赖项。KafkaUtils``spark-streaming-kafka-0-10_2.12 - 为执行程序配置足够的内存 - 由于接收的数据必须存储在内存中,因此必须为执行程序配置足够的内存来保存接收的数据。请注意,如果要执行 10 分钟的窗口操作,系统必须在内存中保留至少最后 10 分钟的数据。因此,应用程序的内存要求取决于其中使用的操作。
- 配置检查点 - 如果流应用程序需要它,则必须将Hadoop API兼容容错存储中的目录(例如HDFS,S3等)配置为检查点目录和流应用程序,其编写方式是检查点信息可用于故障恢复。有关更多详细信息,请参阅检查点部分。
- 配置应用程序驱动程序的自动重新启动 - 若要从驱动程序故障中自动恢复,用于运行流式处理应用程序的部署基础结构必须监视驱动程序进程,并在驱动程序失败时重新启动驱动程序。不同的集群管理器有不同的工具来实现这一点。
- Spark 独立 - 可以提交 Spark 应用程序驱动程序以在 Spark 独立群集中运行(请参阅群集部署模式),即应用程序驱动程序本身在其中一个工作节点上运行。此外,可以指示独立集群管理器监督驱动程序,并在驱动程序由于非零退出代码或由于运行驱动程序的节点故障而失败时重新启动驱动程序。有关更多详细信息,请参阅 Spark 独立指南中的群集模式和监督。
- YARN - Yarn 支持用于自动重新启动应用程序的类似机制。有关更多详细信息,请参阅 YARN 文档。
- Mesos - Marathon 已被用于通过 Mesos 实现这一目标。
- 配置预写日志 - 自 Spark 1.2 起,我们引入了预写日志以实现强大的容错保证。如果启用,则从接收方接收的所有数据都将写入配置检查点目录中的预写日志中。这可以防止驱动程序恢复时丢失数据,从而确保零数据丢失(在容错语义部分中进行了详细讨论)。可以通过将配置参数设置为 来启用此功能。但是,这些更强的语义可能会以单个接收方的接收吞吐量为代价。这可以通过并行运行更多接收器来纠正,以提高聚合吞吐量。此外,建议在启用预写日志时禁用 Spark 中接收的数据的复制,因为日志已存储在复制的存储系统中。这可以通过将输入流的存储级别设置为 来完成。使用 S3(或任何不支持刷新的文件系统)进行预写日志时,请记住启用 和 。有关更多详细信息,请参阅 Spark 流式处理配置。请注意,启用 I/O 加密时,Spark 不会对写入预写日志的数据进行加密。如果需要对预写日志数据进行加密,则应将其存储在本机支持加密的文件系统中。
spark.streaming.receiver.writeAheadLog.enable``true``StorageLevel.MEMORY_AND_DISK_SER``spark.streaming.driver.writeAheadLog.closeFileAfterWrite``spark.streaming.receiver.writeAheadLog.closeFileAfterWrite - 设置最大接收速率 - 如果群集资源不够大,使流式处理应用程序无法像接收数据一样快地处理数据,则可以通过设置记录/秒的最大速率限制来限制接收器的速率。请参阅接收器和直接 Kafka 方法的配置参数。在 Spark 1.5 中,我们引入了一个名为”背压”的功能,无需设置此速率限制,因为 Spark 流会自动计算出速率限制,并在处理条件发生变化时动态调整它们。可以通过将配置参数设置为 来启用此背压。
升级应用程序代码
如果正在运行的 Spark 流式处理应用程序需要使用新的应用程序代码进行升级,则有两种可能的机制。
- 升级后的 Spark 流式处理应用程序将启动并与现有应用程序并行运行。一旦新一个(接收与旧数据相同的数据)已经预热并准备好进入黄金时段,旧一个就可以被关闭。请注意,对于支持将数据发送到两个目标(即早期和升级的应用程序)的数据源,可以执行此操作。
- 现有应用程序正常关闭(有关正常关闭选项,请参阅
StreamingContext.stop(...)或JavaStreamingContext.stop(...),这可确保在关闭之前完全处理已接收的数据。然后可以启动升级的应用程序,该应用程序将从先前应用程序中断的同一点开始处理。请注意,这只能使用支持源端缓冲的输入源(如 Kafka)来完成,因为在以前的应用程序关闭且升级后的应用程序尚未启动时,需要缓冲数据。并且无法从升级前代码的早期检查点信息重新启动。检查点信息实质上包含序列化的 Scala/Java/Python 对象,尝试使用新的、修改过的类反序列化对象可能会导致错误。在这种情况下,请使用不同的检查点目录启动升级后的应用,或删除以前的检查点目录。
监控应用程序
除了 Spark 的监控功能之外,还有特定于 Spark Streaming 的其他功能。使用StreamingContext时,Spark Web UI会显示一个附加选项卡,其中显示有关正在运行的接收器(接收器是否处于活动状态,收到的记录数,接收器错误等)和已完成批处理(批处理时间,排队延迟等)的统计信息。这可用于监视流式处理应用程序的进度。Streaming
Web UI 中的以下两个指标尤其重要:
- 处理时间 - 处理每批数据的时间。
- 计划延迟 - 批处理在队列中等待处理先前批处理完成的时间。
如果批处理时间始终大于批处理间隔和/或排队延迟不断增加,则表明系统无法像生成批处理批处理时那样快速处理批处理,并且正在落后。在这种情况下,请考虑减少批处理时间。
Spark 流式处理程序的进度也可以使用 StreamingListener 接口进行监视,该接口允许您获取接收方状态和处理时间。请注意,这是一个开发人员API,将来可能会对其进行改进(即,报告的更多信息)。
性能调优
从群集上的 Spark 流式处理应用程序获得最佳性能需要一些调整。本节介绍一些参数和配置,可以调整这些参数和配置以提高应用程序的性能。在高层次上,您需要考虑两件事:
- 通过有效使用群集资源,缩短每批数据的处理时间。
- 设置正确的批大小,以便可以像接收数据一样快地处理数据批次(即,数据处理跟上数据引入的步伐)。
减少批处理时间
Spark 中可以进行许多优化,以最大限度地减少每个批次的处理时间。这些已在《调优指南》中详细讨论过。本节重点介绍一些最重要的问题。
数据接收的并行度级别
通过网络接收数据(如 Kafka、套接字等)需要反序列化数据并将其存储在 Spark 中。如果数据接收成为系统中的瓶颈,则考虑并行化数据接收。请注意,每个输入 DStream 都会创建一个接收单个数据流的接收器(在工作计算机上运行)。因此,可以通过创建多个输入 DStream 并将其配置为从源接收数据流的不同分区来实现接收多个数据流。例如,接收两个数据主题的单个 Kafka 输入 DStream 可以拆分为两个 Kafka 输入流,每个输入流仅接收一个主题。这将运行两个接收器,允许并行接收数据,从而提高整体吞吐量。这些多个 DStream 可以合并在一起以创建单个 DStream。然后,应用于单个输入 DStream 的转换可以应用于统一流。这按如下方式完成。
1 | val numStreams = 5 |
另一个应该考虑的参数是接收器的块间隔,它由配置参数确定。对于大多数接收器,接收到的数据在存储在Spark的内存中之前被合并成数据块。每个批处理中的块数决定了将在类似地图的转换中用于处理接收到的数据的任务数。每个接收方每个批次的任务数约为(批次间隔/块间隔)。例如,200 毫秒的块间隔将每 2 个批次创建 10 个任务。如果任务数太少(即少于每台计算机的核心数),则效率低下,因为不会使用所有可用核心来处理数据。若要增加给定批处理间隔的任务数,请减少块间隔。但是,建议的最小块间隔值约为 50 毫秒,低于此值,任务启动开销可能是一个问题。spark.streaming.blockInterval
使用多个输入流/接收器接收数据的替代方法是显式地对输入数据流进行重新分区(使用 )。这会在进一步处理之前,将接收到的数据批次分布到群集中指定数量的计算机上。inputStream.repartition(<number of partitions>)
有关直接流式传输,请参阅 Spark Streaming + Kafka 集成指南
数据处理中的并行度级别
如果在计算的任何阶段使用的并行任务数不够高,则群集资源可能未得到充分利用。例如,对于分布式 reduce 操作(如 和 ),并行任务的默认数目由配置属性控制。您可以将并行度级别作为参数传递(请参阅 PairDStreamFunctions 文档),或设置配置属性以更改默认值。reduceByKey``reduceByKeyAndWindow``spark.default.parallelism``spark.default.parallelism
数据序列化
通过调整序列化格式,可以减少数据序列化的开销。对于流式处理,有两种类型的数据正在序列化。
- 输入数据:默认情况下,通过接收器接收的输入数据存储在执行器的内存中,StorageLevel.MEMORY_AND_DISK_SER_2。也就是说,数据被序列化为字节以减少GC开销,并复制以容忍执行程序故障。此外,数据首先保留在内存中,并且仅当内存不足以保存流式计算所需的所有输入数据时才溢出到磁盘。这种序列化显然会产生开销 - 接收方必须反序列化接收的数据,并使用 Spark 的序列化格式对其进行重新序列化。
- 流式处理操作生成的持久化 RDD:流式处理计算生成的 RDD 可以持久保存在内存中。例如,窗口操作将数据保留在内存中,因为它们将被多次处理。但是,与 Spark Core 默认的 StorageLevel.MEMORY_ONLY 不同,流式处理计算生成的持久化 RDD 默认使用StorageLevel.MEMORY_ONLY_SER(即序列化)进行持久化,以最大程度地减少 GC 开销。
在这两种情况下,使用 Kryo 序列化都可以减少 CPU 和内存开销。有关更多详细信息,请参阅 Spark 调优指南。对于 Kryo,请考虑注册自定义类并禁用对象引用跟踪(请参阅配置指南中的 Kryo 相关配置)。
在需要为流式处理应用程序保留的数据量不大的特定情况下,将数据(两种类型)保留为反序列化对象可能会很可行,而不会产生过多的 GC 开销。例如,如果使用几秒钟的批处理间隔且没有窗口操作,则可以尝试通过相应地显式设置存储级别来禁用持久化数据中的序列化。这将减少由于序列化而导致的 CPU 开销,从而有可能在不产生太多 GC 开销的情况下提高性能。
任务启动开销
如果每秒启动的任务数很高(例如,每秒 50 个或更多),则向执行程序发送任务的开销可能很大,并且很难实现亚秒级延迟。可以通过以下更改来减少开销:
- 执行模式:在独立模式或粗粒度 Mesos 模式下运行 Spark 可比细粒度 Mesos 模式获得更好的任务启动时间。有关更多详细信息,请参阅在 Mesos 上运行指南。
这些更改可以将批处理时间减少 100 毫秒,从而使亚秒级批大小可行。
设置正确的批处理间隔
为了使在群集上运行的 Spark 流式处理应用程序保持稳定,系统应该能够像接收数据一样快地处理数据。换句话说,批量数据的处理速度应与生成数据的速度一样快。通过监视流式处理 Web UI 中的处理时间(其中批处理时间应小于批处理间隔),可以找到应用程序是否属于这种情况。
根据流式计算的性质,使用的批处理间隔可能会对应用程序在一组固定的群集资源上可以维持的数据速率产生重大影响。例如,让我们考虑前面的 WordCountNetwork 示例。对于特定的数据速率,系统可能能够每2秒(即,2秒的批处理间隔)跟上报告字数,但不是每500毫秒。因此,需要设置批次间隔,以便可以维持生产中的预期数据速率。
为应用程序确定正确的批大小是使用保守的批处理间隔(例如,5-10 秒)和低数据速率对其进行测试。若要验证系统是否能够跟上数据速率,可以检查每个已处理批次所经历的端到端延迟值(在 Spark 驱动程序 log4j 日志中查找”总延迟”,或使用流式处理听信器接口)。如果将延迟保持为与批大小相当,则系统是稳定的。否则,如果延迟不断增加,则意味着系统无法跟上,因此不稳定。一旦您了解了稳定的配置,就可以尝试提高数据速率和/或减小批大小。请注意,由于临时数据速率增加而导致的延迟暂时增加可能很好,只要延迟减小到较低值(即小于批大小)。
内存调整
优化指南中已经详细讨论了调整 Spark 应用程序的内存使用情况和 GC 行为。强烈建议您阅读该书。在本节中,我们将专门讨论 Spark 流式处理应用程序上下文中的一些优化参数。
Spark 流式处理应用程序所需的群集内存量在很大程度上取决于所使用的转换类型。例如,如果要对过去 10 分钟的数据使用窗口操作,则集群应具有足够的内存,以便在内存中保存 10 分钟的数据。或者,如果您想与大量按键一起使用,那么必要的内存将很高。相反,如果要执行简单的映射-过滤器-存储操作,则必要的内存将不足。updateStateByKey
通常,由于通过接收器接收的数据与StorageLevel.MEMORY_AND_DISK_SER_2一起存储,因此不适合内存的数据将溢出到磁盘。这可能会降低流式处理应用程序的性能,因此建议根据流式处理应用程序的要求提供足够的内存。最好尝试以小规模查看内存使用情况并进行相应的估计。
内存调整的另一个方面是垃圾回收。对于需要低延迟的流式处理应用程序,不希望 JVM 垃圾回收导致大量暂停。
有几个参数可以帮助您调整内存使用情况和 GC 开销:
- DStream 的持久性级别:如前所述,在数据序列化部分中,输入数据和 RDD 默认保留为序列化字节。与反序列化持久性相比,这减少了内存使用量和 GC 开销。启用 Kryo 序列化可进一步减少序列化大小和内存使用量。通过压缩可以进一步减少内存使用量(参见 Spark 配置),但代价是 CPU 时间。
spark.rdd.compress - 清除旧数据:默认情况下,将自动清除 DStream 转换生成的所有输入数据和持久化 RDD。Spark 流式处理根据使用的转换来决定何时清除数据。例如,如果您使用的是 10 分钟的窗口操作,则 Spark 流式处理将保留最后 10 分钟左右的数据,并主动丢弃较旧的数据。通过设置 , 数据可以保留更长的时间(例如,以交互方式查询较旧的数据)。
streamingContext.remember - CMS 垃圾回收器:强烈建议使用并发标记和扫描 GC,以保持与 GC 相关的暂停始终保持在较低水平。尽管已知并发 GC 会降低系统的整体处理吞吐量,但仍建议使用 GC 来实现更一致的批处理时间。确保在驱动程序(使用 in)和执行程序(使用 Spark 配置)上设置 CMS GC。
--driver-java-options``spark-submit``spark.executor.extraJavaOptions - 其他提示:要进一步减少 GC 开销,下面是一些其他提示供您尝试。
- 使用存储级别保留 RDD。有关更多详细信息,请参阅 Spark 编程指南。
OFF_HEAP - 使用更多堆大小较小的执行程序。这将减少每个 JVM 堆中的 GC 压力。
- 使用存储级别保留 RDD。有关更多详细信息,请参阅 Spark 编程指南。
要记住的要点:
- DStream 与单个接收器相关联。为了实现读取并行性,需要创建多个接收器,即多个DStream。接收器在执行器内运行。它占据一个核心。确保在预订接收器插槽后有足够的内核进行处理,即 应考虑接收器插槽。接收方以轮循机制方式分配给执行程序。
spark.cores.max - 从流源接收数据时,接收方会创建数据块。每隔一毫秒就会生成一个新的数据块。在 batchInterval 期间创建 N 个数据块,其中 N = batchInterval/blockInterval。这些块由当前执行器的 BlockManager 分发给其他执行器的块管理器。之后,在驱动程序上运行的网络输入跟踪器将被告知块位置以进行进一步处理。
- 在驱动程序上为批处理期间创建的块创建 RDD。在批处理期间生成的块是 RDD 的分区。每个分区都是 spark 中的一个任务。blockInterval== batchinterval 意味着创建了一个分区,并且可能在本地进行处理。
- 块上的映射任务在执行器(一个接收块,另一个复制块的位置)中处理,该执行器具有块而不考虑块间隔,除非非本地调度启动。拥有更大的区块意味着更大的区块。较高的 值 会增加处理本地节点上的块的几率。需要在这两个参数之间找到平衡,以确保较大的块在本地处理。
spark.locality.wait - 无需依赖 batchInterval 和 blockInterval,您可以通过调用 来定义分区数。这会随机重新排列 RDD 中的数据,以创建 n 个分区。是的,为了提高并行性。虽然是以洗牌为代价的。RDD 的处理由驾驶员的作业分拣员安排为作业。在给定的时间点,只有一个作业处于活动状态。因此,如果一个作业正在执行,则其他作业将排队。
inputDstream.repartition(n) - 如果您有两个 dstream,则将形成两个 RDD,并且将创建两个作业,这些作业将一个接一个地安排。为避免这种情况,可以合并两个 dstream。这将确保为 d 流的两个 RDD 形成一个联合 RDD。然后,该工会RDD被视为单一工作。但是,RDD 的分区不受影响。
- 如果批处理时间超过批处理间隔,那么显然接收方的内存将开始填满,并最终引发异常(最有可能是BlockNotFoundException)。目前,无法暂停接收机。使用SparkConf配置,接收器的速率可以受到限制。
spark.streaming.receiver.maxRate
容错语义
在本节中,我们将讨论 Spark 流式处理应用程序在发生故障时的行为。
背景
为了理解 Spark Streaming 提供的语义,让我们记住 Spark 的 RDD 的基本容错语义。
- RDD 是不可变的、确定性可重计算的分布式数据集。每个 RDD 都会记住用于创建容错输入数据集的确定性操作的沿袭。
- 如果RDD的任何分区由于工作线程节点故障而丢失,则可以使用操作沿袭从原始容错数据集重新计算该分区。
- 假设所有 RDD 转换都是确定性的,则无论 Spark 群集中发生故障,最终转换的 RDD 中的数据都将始终相同。
Spark 对 HDFS 或 S3 等容错文件系统中的数据进行操作。因此,从容错数据生成的所有RDD也是容错的。但是,Spark 流的情况并非如此,因为在大多数情况下,数据是通过网络接收的(除非使用时)。为了对所有生成的 RDD 实现相同的容错属性,将在群集中工作线程节点中的多个 Spark 执行程序之间复制接收到的数据(默认复制因子为 2)。这导致系统中的两种数据在发生故障时需要恢复:fileStream
- 接收和复制的数据 - 此数据在单个工作线程节点发生故障后仍会继续存在,因为该数据的副本存在于其他节点之一上。
- 已接收但缓冲以进行复制的数据 - 由于不会复制此数据,因此恢复此数据的唯一方法是从源中再次获取它。
此外,我们应该关注两种故障:
- 工作节点故障 - 任何运行执行程序的工作线程节点都可能失败,并且这些节点上的所有内存中数据都将丢失。如果任何接收器在故障节点上运行,则其缓冲数据将丢失。
- 驱动程序节点故障 - 如果运行 Spark 流式处理应用程序的驱动程序节点失败,则显然 SparkContext 将丢失,并且所有执行程序及其内存中数据都将丢失。
有了这些基本知识,让我们了解一下 Spark 流的容错语义。
定义
流系统的语义通常根据系统可以处理每条记录的次数来捕获。系统可以在所有可能的操作条件下提供三种类型的保证(尽管出现故障等)。
- 最多一次:每条记录将处理一次或根本不处理。
- 至少一次:每条记录将被处理一次或多次。这比最多一次更强大,因为它确保不会丢失任何数据。但可能会有重复。
- 正好一次:每条记录将只处理一次 - 不会丢失任何数据,也不会多次处理任何数据。这显然是三者中最有力的保证。
基本语义
从广义上讲,在任何流处理系统中,处理数据都有三个步骤。
- 接收数据:使用接收器或其他方式从源接收数据。
- 转换数据:使用 DStream 和 RDD 转换转换接收到的数据。
- 推出数据:最终转换后的数据被推送到外部系统,如文件系统、数据库、仪表板等。
如果流应用程序必须实现端到端的精确一次保证,那么每个步骤都必须提供一次完全相同的保证。也就是说,每个记录必须只接收一次,转换一次,然后推送到下游系统一次。让我们在 Spark 流式处理的上下文中了解这些步骤的语义。
- 接收数据:不同的输入源提供不同的保证。这将在下一小节中详细讨论。
- 转换数据:由于RDD提供的保证,所有已收到的数据将只处理一次。即使出现故障,只要接收到的输入数据可访问,最终转换的RDD将始终具有相同的内容。
- 推出数据:默认情况下,输出操作确保至少一次语义,因为它取决于输出操作的类型(幂等或不幂等)和下游系统的语义(是否支持事务)。但是用户可以实现自己的事务机制来实现恰好一次的语义。本节稍后将对此进行更详细的讨论。
接收数据的语义
不同的输入源提供不同的保证,从至少一次到恰好一次不等。阅读了解更多详情。
使用文件
如果所有输入数据都已存在于容错文件系统(如HDFS)中,则Spark Streaming始终可以从任何故障中恢复并处理所有数据。这给出了恰好一次的语义,这意味着无论什么失败,所有数据都将被精确地处理一次。
使用基于接收器的源
对于基于接收器的输入源,容错语义取决于故障场景和接收器类型。如前所述,有两种类型的接收器:
- 可靠接收器 - 这些接收器仅在确保已复制接收的数据后才确认可靠的来源。如果此类接收器发生故障,则源将不会收到缓冲(未复制)数据的确认。因此,如果接收方重新启动,源将重新发送数据,并且不会因故障而丢失任何数据。
- 不可靠的接收器 - 此类接收器不发送确认,因此当它们由于工作线程或驱动程序故障而失败时可能会丢失数据。
根据所使用的接收器类型,我们实现以下语义。如果工作线程节点发生故障,则使用可靠的接收器不会丢失数据。对于不可靠的接收器,接收但未复制的数据可能会丢失。如果驱动程序节点发生故障,则除了这些损失之外,在内存中接收和复制的所有过去数据都将丢失。这将影响有状态转换的结果。
为了避免过去接收数据的这种丢失,Spark 1.2引入了预写日志,将接收到的数据保存到容错存储中。启用预写日志和可靠的接收器后,数据丢失为零。在语义方面,它提供了至少一次的保证。
下表总结了失败下的语义:
| 部署方案 | 工作线程故障 | 驱动程序故障 |
|---|---|---|
| Spark 1.1 或更早版本,或 Spark 1.2 或更高版本,不带预写日志 | 使用不可靠的接收器丢失缓冲数据 使用可靠的接收器 实现零数据丢失 至少一次语义 | 不可靠的接收器丢失的缓冲数据 所有接收器丢失的过去数据 未定义的语义 |
| Spark 1.2 或更高版本,带有预写日志 | 使用可靠的接收器 实现零数据丢失 至少一次语义 | 通过可靠的接收器和文件 实现零数据丢失 至少一次语义 |
使用 Kafka Direct API
在 Spark 1.3 中,我们引入了一个新的 Kafka Direct API,它可以确保 Spark Streaming 只接收一次所有 Kafka 数据。除此之外,如果您实现精确一次的输出操作,则可以实现端到端的精确一次保证。《Kafka 集成指南》进一步讨论了这种方法。
输出操作的语义
输出操作(如 )至少具有一次语义,也就是说,在工作线程发生故障时,转换后的数据可能会多次写入外部实体。虽然这对于使用操作保存到文件系统是可以接受的(因为文件只会被相同的数据覆盖),但可能需要额外的工作来实现恰好一次的语义。有两种方法。foreachRDD``saveAs***Files
- 幂等更新:多次尝试始终写入相同的数据。例如,始终将相同的数据写入生成的文件。
saveAs***Files - 事务性更新:所有更新都是以事务方式进行的,因此更新恰好以原子方式进行一次。执行此操作的一种方法是以下方法。
- 使用 RDD 的批处理时间(在 中可用)和分区索引来创建标识符。此标识符唯一标识流式处理应用程序中的 Blob 数据。
foreachRDD - 使用标识符以事务方式(即,正好一次,原子方式)使用此 Blob 更新外部系统。也就是说,如果标识符尚未提交,请以原子方式提交分区数据和标识符。否则,如果已提交此操作,请跳过更新。
- 使用 RDD 的批处理时间(在 中可用)和分区索引来创建标识符。此标识符唯一标识流式处理应用程序中的 Blob 数据。



