Hadoop模块 common 公共通用模块
HDFS 文件存储
YARN 资源管理
MapReduce 计算框架
Hadoop集群安装部署 虚拟机配置 linux网络配置 1.修改主机名称 /etc/hostname
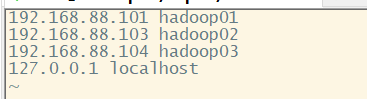
Host文件配置 三台虚拟机之间通信名称代替ip
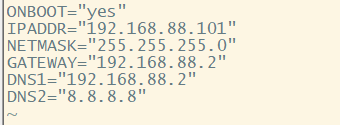
2.网络参数配置 配置静态ip
3.测试网卡配置
若修改vmware默认初始网段,出现无法ping通外网在上图虚拟网络编辑器还原默认配置,使用还原后的网段即可.
SSH服务配置 免密登录 1.生成私匙和公匙
将共匙加入authorized_keys文件, 复制公匙到自己以及hadoop02和hadoop03 实现免密登录,每一台都要将公匙复制到其他主机的authorized_keys文件
1 2 3 ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03
防火墙配置 1 2 3 firewall-cmd --zone=public --add-port=9000/tcp --permanent firewall-cmd --zone=public --add-port=50075/tcp --permanent firewall-cmd --zone=public --add-port=8088/tcp --permanent
hdfs 9000 50070 50010
yarn 8030 8031 8032 8088
journalnode 8485
zookeeper 2181 2888 3888
放开端口需重载防火墙配置
查看一下开放的端口
1 firewall-cmd --zone=public --list-ports
常用的端口如下
JDK安装 运行hadoop需要先安装java环境,一般选择自己配置jdk,也可yum或apt安装
Hadoop安装和集群配置 1.将下载的hadoop-bin安装包上传至服务器
2.解压
3.配置环境变量 1 2 3 4 export HADOOP_HOME=/export/servers/hadoop-2.9.2export PATH=$PATH :$HADOOP_HOME /bin:$HADOOP_HOME /sbinexport HADOOP_CLASSPATH=$HADOOP_HOME /lib/*export HADOOP_CLASSPATH=$HADOOP_CLASSPATH :$HIVE_HOME /lib/*
需要注意的是配置环境变量的时候若有两个path 一定要记得两个都要在前面加$符号
4.验证
主节点配置文件 hadoop-env.sh
1 export JAVA_HOME=/export/servers/jdk1.8.0
常用端口core-site.xml 官网core-default
高可用ha配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>hadoop.http.filter.initializers</name> <value>org.apache.hadoop.security.AuthenticationFilterInitializer</value> </property> <!--定义用于HTTPweb控制台的身份验证。支持的值是:simple|kerberos|#AUTHENTICATION_HANDLER_CLASSNAME#--> <property> <name>hadoop.http.authentication.type</name> <value>simple</value> </property> <!-- 签名秘密文件,用于对身份验证令牌进行签名。 对于集群中的每个服务,ResourceManager, NameNode, DataNode和NodeManager,应该使用不同的secret。 这个文件应该只有运行守护进程的Unix用户可以读。 --> <property> <name>hadoop.http.authentication.signature.secret.file</name> <value>/root/hadoop-http-auth-user</value> </property> <!--禁止匿名用户访问--> <property> <name>hadoop.http.authentication.simple.anonymous.allowed</name> <value>false</value> </property> </configuration>
hdfs-site.xml 官网hdfs-default
高可用ha配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 <configuration> <!--副本数量--> <property> <name>dfs.replication</name> <value>2</value> </property> <!--元数据信息位置--> <property> <name>dfs.namenode.name.dir</name> <value>file:/export/data/hadoop/name</value> </property> <!--数据位置--> <property> <name>dfs.datanode.data.dir</name> <value>file:/export/data/hadoop/data</value> </property> <!--开启WEB-HDFS--> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <!--ha集群名称--> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <!--两台namenode名称--> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!--nn1的通信地址--> <!--RPC通信地址--> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop01:9000</value> </property> <!--http通信地址--> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop01:50070</value> </property> <!--nn2的通信地址--> <!--RPC通信地址--> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop02:9000</value> </property> <!--http通信地址--> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop02:50070</value> </property> <!--高可用集群通过共享数据做热备份--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns1</value> </property> <!--指定journal在本地磁盘的存放位置--> <property> <name>dfs.journalnode.edits.dir</name> <value>/export/data/hadoop/journaldata</value> </property> <!--开启namenode失败自动切换--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--隔离机制自动切换时登录第二台namenode --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <!--journal连接配置--> <property> <name>dfs.qjournal.start-segment.timeout.ms</name> <value>20000</value> </property> <property> <name>dfs.qjournal.select-input-streams.timeout.ms</name> <value>20000</value> </property> <property> <name>dfs.qjournal.write-txns.timeout.ms</name> <value>20000</value> </property> </configuration>
Mapred-site.xml 官网mapred-site
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!--该参数限制输入文件数目,避免namenode出现元数据加载处理瓶颈。 详细说明见“http://blog.csdn.net/fjssharpsword/article/details/70258251” --> <property> <name>mapreduce.job.split.metainfo.maxsize</name> <value>100000000</value> </property> <!--map任务内存总大小 根据任务需要调整大小值--> <property> <name>mapreduce.map.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx3072m</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>8192</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx6144m</value> </property> </configuration>
yarn-site.xml yran常用参数参考
资源管理器负责配置调控CPU,内存,磁盘等分配和使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nodemanager 配置 ================================================= --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>0.0.0.0:23344</value> <description>Address where the localizer IPC is.</description> </property> <property> <name>yarn.nodemanager.webapp.address</name> <value>0.0.0.0:23999</value> <description>NM Webapp address.</description> </property> <!-- HA 配置 =============================================================== --> <!-- Resource Manager Configs --> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 使嵌入式自动故障转移。HA环境启动,与 ZKRMStateStore 配合 处理fencing --> <property> <name>yarn.resourcemanager.ha.automatic-failover.embedded</name> <value>true</value> </property> <!-- 集群名称,确保HA选举时对应的集群 --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--这里RM主备结点需要单独指定,(可选) <property> <name>yarn.resourcemanager.ha.id</name> <value>rm2</value> </property> --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name> <value>5000</value> </property> <!-- ZKRMStateStore 配置 --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <property> <name>yarn.resourcemanager.zk.state-store.address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <!-- Client访问RM的RPC地址 (applications manager interface) --> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop01:23140</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop02:23140</value> </property> <!-- AM访问RM的RPC地址(scheduler interface) --> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop01:23130</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop02:23130</value> </property> <!-- RM admin interface --> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>hadoop01:23141</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>hadoop02:23141</value> </property> <!--NM访问RM的RPC端口 --> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop01:23125</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop02:23125</value> </property> <!-- RM web application 地址 --> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop01:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop02:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address.rm1</name> <value>hadoop01:23189</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address.rm2</name> <value>hadoop02:23189</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log.server.url</name> <value>http://hadoop01:19888/jobhistory/logs</value> </property> <!--节点cpu memory分配--> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>10240</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>5</value> </property> <!--container 限制--> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> <discription>单个任务可申请最大内存,默认8192MB</discription> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>5</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5</value> </property> </configuration>
slaves
配置分发
1 2 3 4 5 scp /etc/profile hadoop02:/etc scp /etc/profile hadoop03:/etc cd /export/servers/hadoop-2.9.2/etc/hadoopscp ./* hadoop02:$PWD scp ./* hadoop03:$PWD
zookeeper安装并配置 1.下载并解压 2.配置环境变量 3.配置zoo.cfg 进入安装目录下conf下新建zoo.cfg文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/export/data/zookeeper clientPort=2181 admin.serverPort=6888 maxClientCnxns=60 standaloneEnabled=false admin.enableServer=true server.1=hadoop01:2888:3888 server.2=hadoop01:2888:3888 server.3=hadoop01:2888:3888 4lw.commands.whitelist=*
添加myid文件 进入zoo.cfg文件的dataDir目录新建myid文件 并输入id值
hadoop01输入值1,hadoop02输入值为2,hadoop03输入值为3
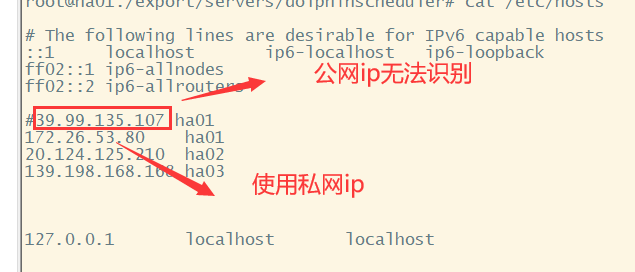
当使用云服务器搭建集群时
Hadoop集群启动测试 1.启动各个节点的zookeeper服务
2.启动集群监控namenode的管理日志journalNode
1 2 3 hadoop-daemons.sh start journalnode hdfs –daemon start journalnode
可以不用单独启动,在启动hadoop集群的时候会自动启动(如果配置了的journalnode情况)
3.在node-01上格式化namenode,并分发到node-02
1 2 3 hdfs namenode -format scp –r /export/data/hadoop hadoop02:/export/data
若初始化时出现下面错误
错误原因:
解决方法:
方法①:手动启动namenode,避免了网络延迟等待journalnode的步骤,一旦两个namenode连入journalnode,实现了选举,则不会出现失败情况。
方法②:先启动journalnode然后再运行start-dfs.sh。
方法③:把namenode对journalnode的容错次数或时间调成更大的值,保证能够对正常的启动延迟、网络延迟能容错。在hdfs-site.xml中修改ipc参数,namenode对journalnode检测的重试次数,默认为10次,每次1000ms,故网络情况差需要增加。具体修改信息为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <property> <name>ipc.client.connect.max.retries</name> <value>100</value> <description>Indicates the number of retries a client will make to establish a server connection. </description> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection. </description> </property>
原文链接
4.在node-01上格式化ZKFC 这个命令必须自己敲出来不能复制
1 2 3 hdfs zkfc –formatZK -force start-dfs.sh start-yarn.sh
结果 3台均正常启动dfs 和yarn
如果有漏掉的机器没有启动 则可以用 在漏掉的机器上执行启动
1 2 3 4 5 hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode yarn-daemon.sh start resourcemanager yarn-daemon.sh start secondarymanager yarn-daemon.sh start nodemanager
hadoop job执行流程
dataInput–>split–>Mapper–>Combine–>(产出临时数据–>Partition–>Sort–>Reducer–>最终数据。
Mapper阶段 Mapper的数量由输入的大小和个数决定。在默认情况下,最终input占据了多少block,就应该启动多少个Mapper。500M的数据分成四个block(128M*4)就是4个mapper。
分区 排序 溢写 文件合并 partition默认分区 分区器是HashPartitioner 对numReduceTasks取模,模数相同分到同一分区,对key进行排序,当内存缓冲区达到阈值进行溢写到磁盘,产生的多个小文件将合并为一个大文件。分区对应reduce;参考文章
Reduce Reducer将与一个key关联的一组中间数值集归为一个更小的数值集。它的数据来源可能是多个mapper的某个分区,过程就要进行shuffle,然后对收集到的key进行合并;
HDFS的Checkpoint Checkpoint(检查点):因为数据库系统或者像HDFS这样的分布式文件系统,对文件数据的修改不是直接写回到磁盘的,很多操作是先缓存到内存的Buffer中,当遇到一个检查点Checkpoint时,系统会强制将内存中的数据写回磁盘,当然此时才会记录日志,从而产生持久的修改状态。
在介绍Checkpoint之前,先来看看Namenode上面有些什么数据:
edits HDFS操作的日志记录,没此对HDFS进行修改操作后,都会往edits中记录一条日志;
fsimage HDFS中命名空间、数据块分布、文件属性等信息都存放在fsimage中;
edits是在每次修改HDFS时都会插入记录,那么fsimage则在整个HDFS运行期间不会产生变化,用HDFS官方文档的说法就是:NameNode merges fsimage and edits files only during start up。也就是说,只有在每次启动Namenode时,才会把edits中的操作增加到fsimage中,并且把edits清空。所以fsimage总是记录启动Namenode时的状态,而edits在每次启动时也是空的,它只记录本次启动后的操作日志。
为什么需要checkpoint? 按照fsimage和edits的工作机制,在一次启动后,edits的文件可能会增长到很大,这样在下次启动Namenode时需要花费很长时间来恢复;
checkpoint触发条件 在配置文件中的参数:
时间维度,默认一小时触发一次工作流程 dfs.namenode.checkpoint.period :3600
次数维度,默认100万次触发一次工作流程 dfs.namenode.checkpoint.txns : 1000000
大小维度,默认64M触发一次工作流程 fs.checkpoint.size:67108864。
也就说触发HDFS中Checkpoint的机制有三种,一是时间、次数和日志的大小
checkpoint做了什么 Chekpoint主要干的事情是,将Namenode中的edits和fsimage文件拷贝到Second Namenode上,然后将edits中的操作与fsimage文件merge以后形成一个新的fsimage,这样不仅完成了对现有Namenode数据的备份,而且还产生了持久化操作的fsimage。
最后一步,Second Namenode需要把merge后的fsimage文件upload到Namenode上面,完成Namenode中fsimage的更新。原文
shared.edits.dir 日志文件位置设置 当集群为高可用集群时standbynamenode会读取该目录下edits文件并与fsimage合并为新的fsimage
1 2 3 4 5 6 7 8 9 10 <!--NAMENODE的元数据在journalnode的存放位置--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns1</value> </property> <!--指定journalnode在本地磁盘的存放位置--> <property> <name>dfs.journalnode.edits.dir</name> <value>/export/data/hadoop/journaldata</value> </property>
fsimage fsimage文件位置 1 2 3 4 5 <!--元数据信息位置--> <property> <name>dfs.namenode.name.dir</name> <value>file:/export/data/hadoop/name</value> </property>
利用副本机制故障还原 1.删掉Active NameNode的FSimage和Edits_Log模拟数据丢失
2.将Standby NameNode的FSimage和Edits_Log复制到NN的FSimage和Edits_Log对应的目录下
3.启动挂掉的NameNode原文
HDFS中的fsck命令 查看文件目录的健康信息
查看文件中损坏的块 (-list-corruptfileblocks)
1 hdfs fsck /weblog -list-corruptfileblocks
损坏文件的处理 将损坏的文件移动至/lost+found目录 (-move)
1 hdfs fsck /user/hadoop-twq/cmd -move
删除有损坏数据块的文件 (-delete)
1 hdfs fsck /user/hadoop-twq/cmd -delete
打印文件的Block报告(-blocks) 执行下面的命令,可以查看一个指定文件的所有的Block详细信息,需要和-files一起使用:
1 hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks
如果,我们在上面的命令再加上-locations的话,就是表示还需要打印每一个数据块的位置信息,如下:
hdfs haadmin 命令 -transitionToActive 1 2 3 4 5 hdfs haadmin -transitionToActive -forcemanual nn1 hdfs haadmin -transitionToStandby -forcemanual nn1
-getServiceState 1 2 hdfs haadmin -getServiceState nn1